The goal of these notes is answering the question: Is Learning Feasible?
To do that, we first developed an intuition and then use the Hoeffding Inequality
to formarly explain our inution.
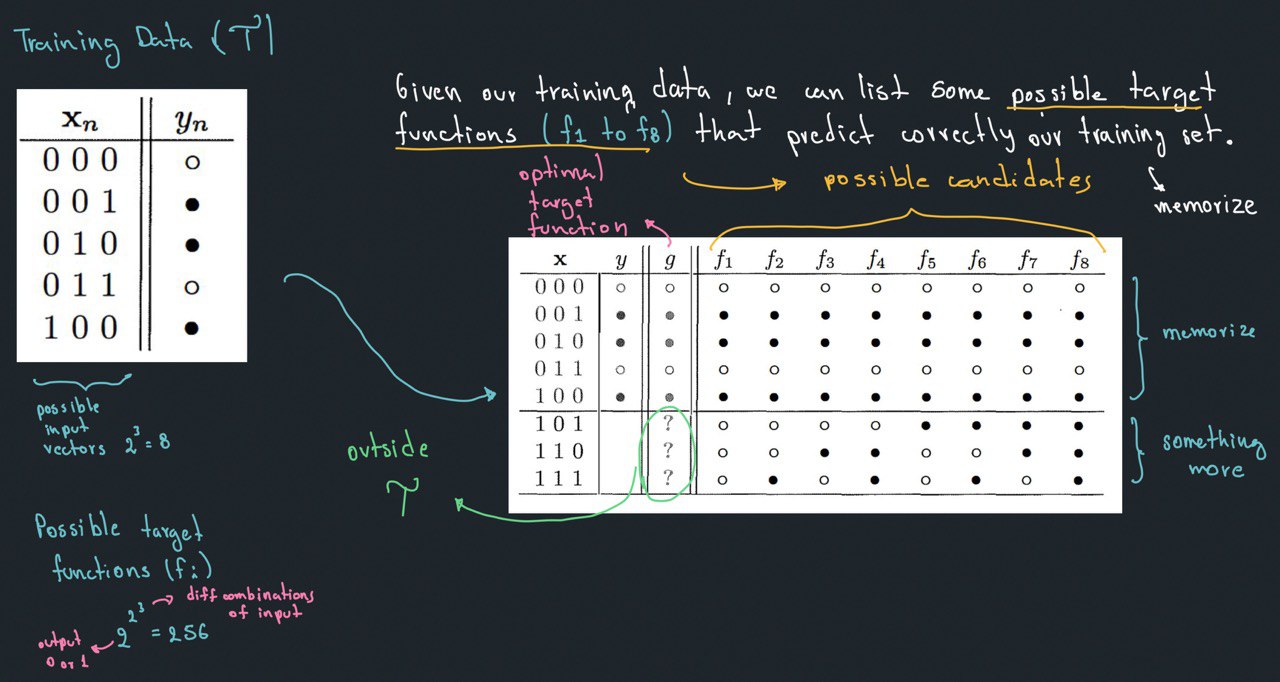
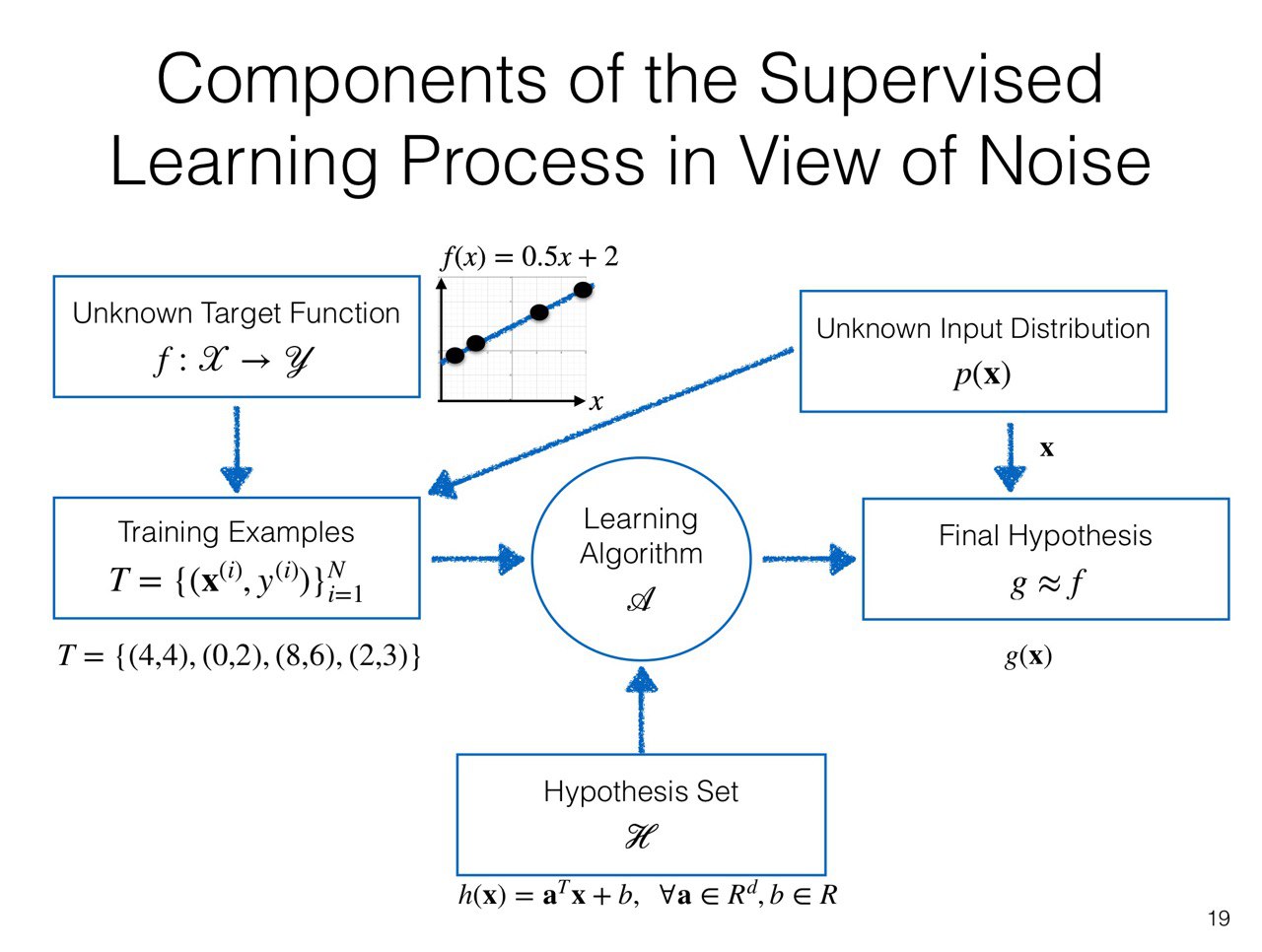
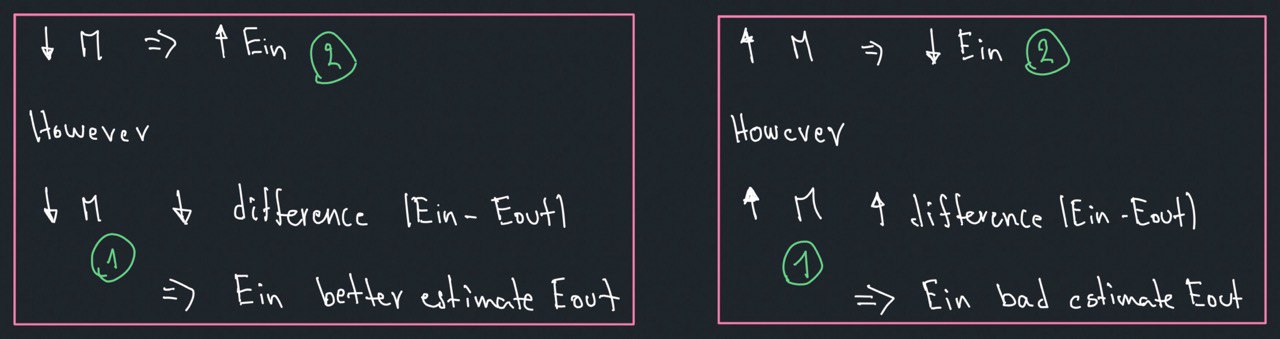
The learner $\mathcal{A}$, in principle, only have limited data (==training set==) to pindown
the theorical entire target function $f(x)$. However, this limited data set could reveal enough
information or not depending of the prespective (discrete or ==probabilitic==), and
we will describe these prespectives later.
First, it's important to define what we understand for feasible learning. Our notion of learning
in this context is the following:
- ==Learning:== A learner is learning if it is able to tell us __anything outside of training set ($\mathcal{T}$)__.
- ==Memorization:== A learner is only memorizing if it only knows the target $f$ for all points in our training set.