Hi, I'm
a computer scientist with experience in AI/ML.
I recently completed a master's degree in AI/ML at the University of Birmingham, fully funded by the Google DeepMind International Scholarship.
I'm currently looking for Research Engineer or ML Engineer position in the field of reinforcement learning and/or large language models.
During my master's program, I focused on state abstractions in RL, representation learning in RL, and bisimulation metrics under the supervision of
Mirco Giacobbe and Leonardo Stella, with
the additional mentorship of Pablo Samuel Castro from Université de Montréal and Google DeepMind,
and Rishabh Kabra from Oxford University and Google DeepMind.
After college, I gained industry experience working as a Machine Learning Engineer at Mobia Latam (start-up)
and DIGEVO.
During my undergraduate studies, I worked as a part-time Junior Researcher at the
Scientific Computing Group, supervised by
Israel Pineda, and at DeepARC Research,
supervised by Eugenio Morocho.
Later, I completed a research internship at KAUST, working on StyleGANs
under the supervision of Peter Wonka.
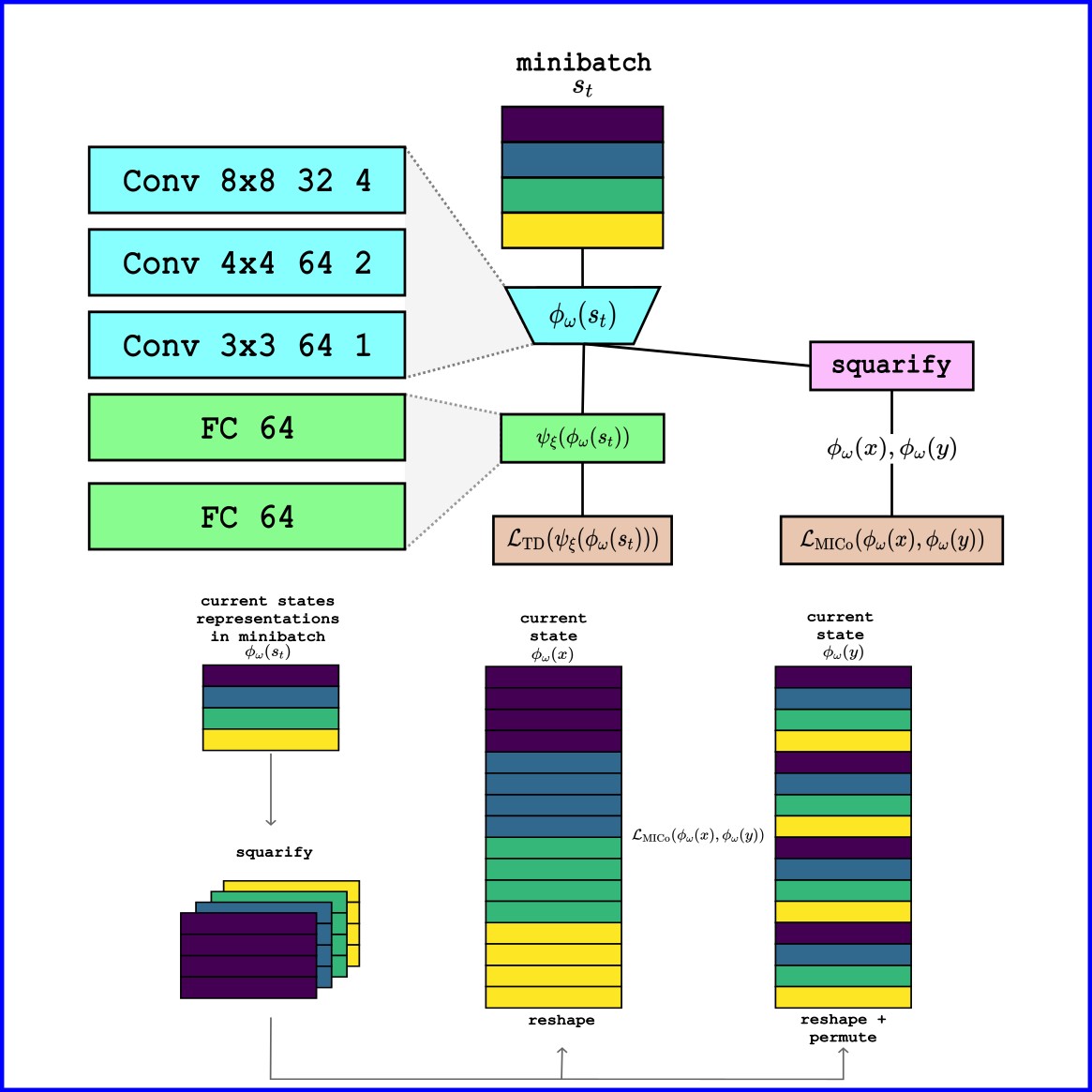
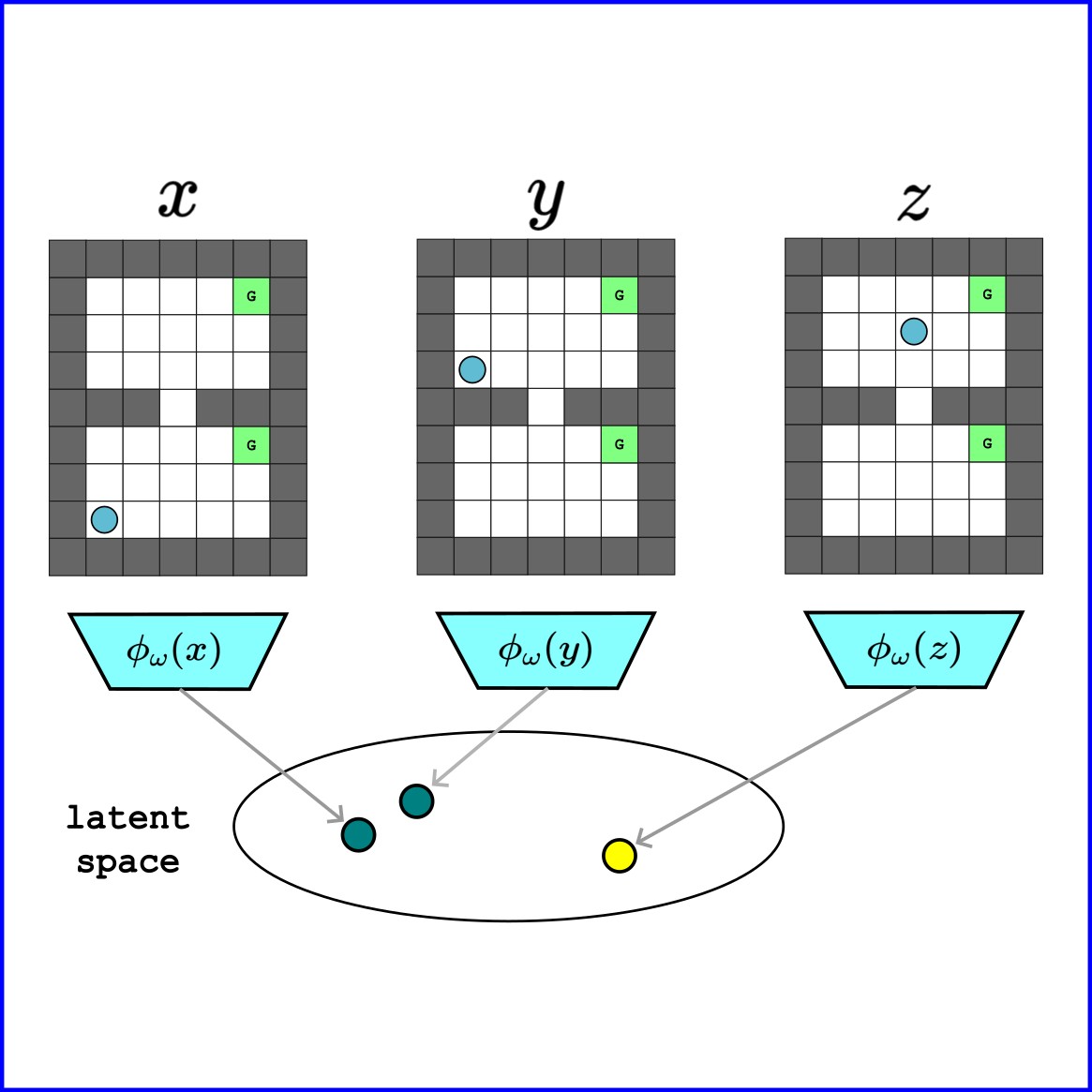
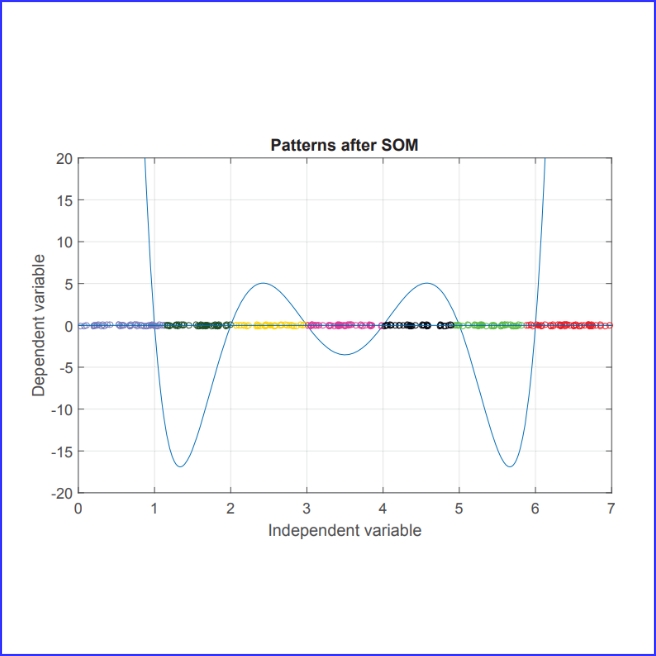
Bisimulation Prioritized Experience Replay (BPER) introduces a novel approach to enhance value-based reinforcement
learning by incorporating a bisimulation metric to prioritize behaviorally relevant transitions.
By balancing traditional TD-error with state behavior similarities, BPER improves data diversity
and learning efficiency, as demonstrated in a 31-state Grid World and pixel-based environments.
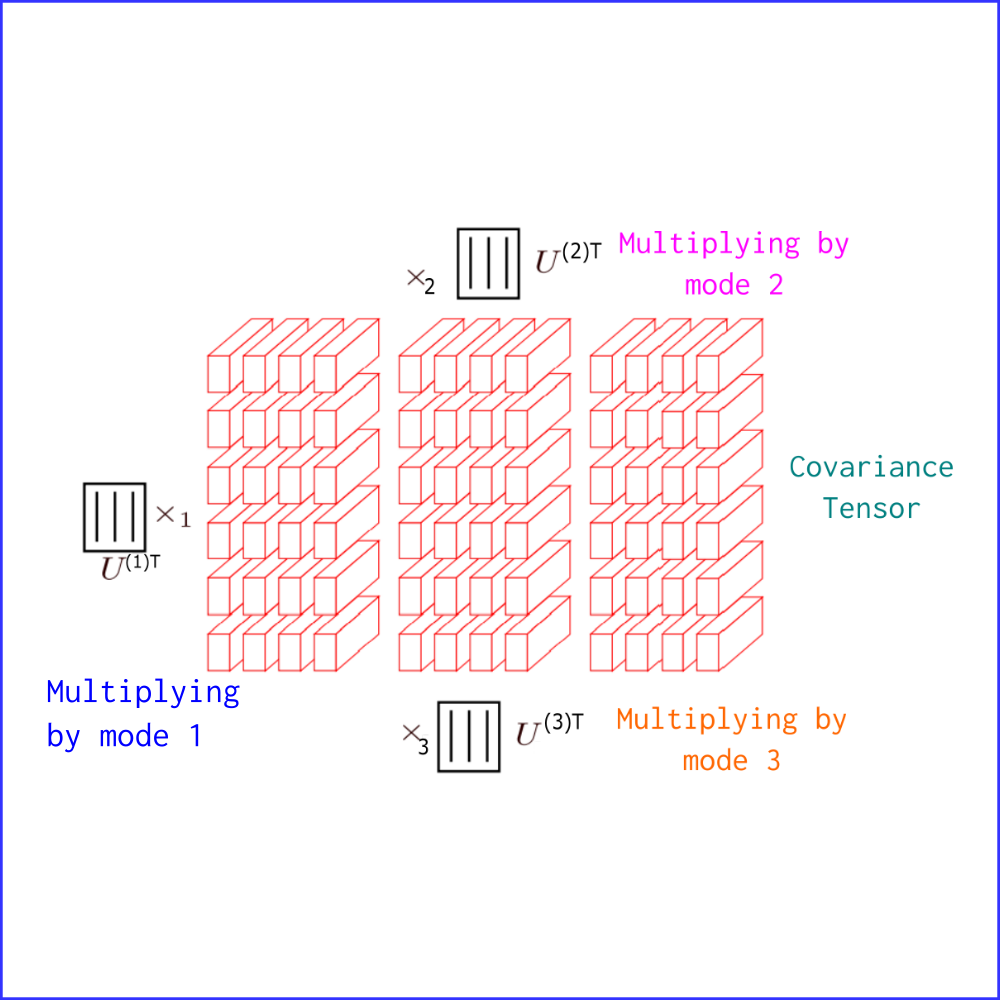
During a single step forward, we compute the covariance tensor
and factorize it by Tucker decomposition to generate kernels
for a CNN. The kernels were then plugged into the CNN
(CovarianceNet) for classification.
We reproduced StyleGAN embedding algorithms, adding further
experimentation such as inpainting, super-resolution,
colorization, morphing, style transfer, and expression transfer.
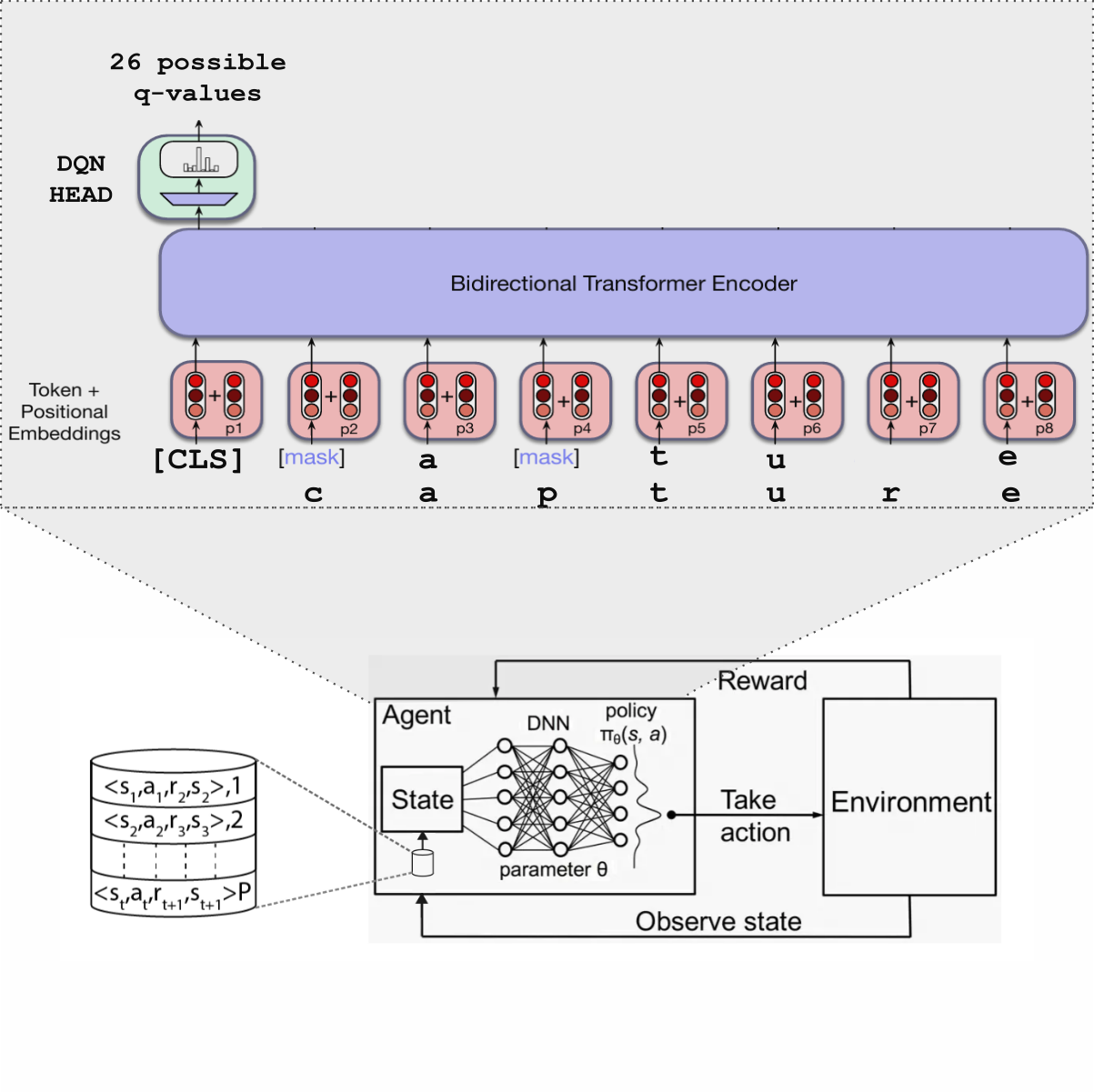
This project integrated a pretrained BERT-based model into a Deep Q-Network (DQN) to enhance
decision-making in the Hangman word game. The model combines contextual learning from BERT with
reinforcement learning, optimizing letter selection via a dynamic reward function based on
character frequency and game progression. Explored LoRA fine-tuning, smaller BERT variants,
and custom Gym environments improving accuracy from 70% to 75% and achieving a 65% success
rate across 113,000 games.
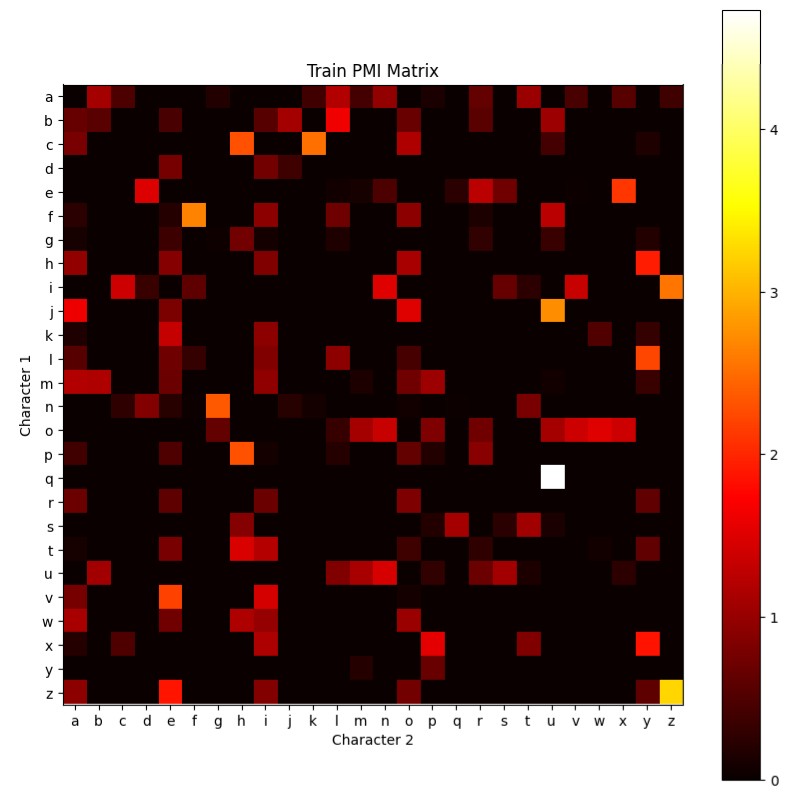
This project aims to fine-tune a BERT-based model, called HangmanNet, for character-level masked language modeling to
play the Hangman game. The model predicts hidden characters by leveraging bidirectional context from both sides of a
word. Additional techniques, such as incorporating prior character frequency and custom data collators, were explored to
improve accuracy, particularly for shorter words.
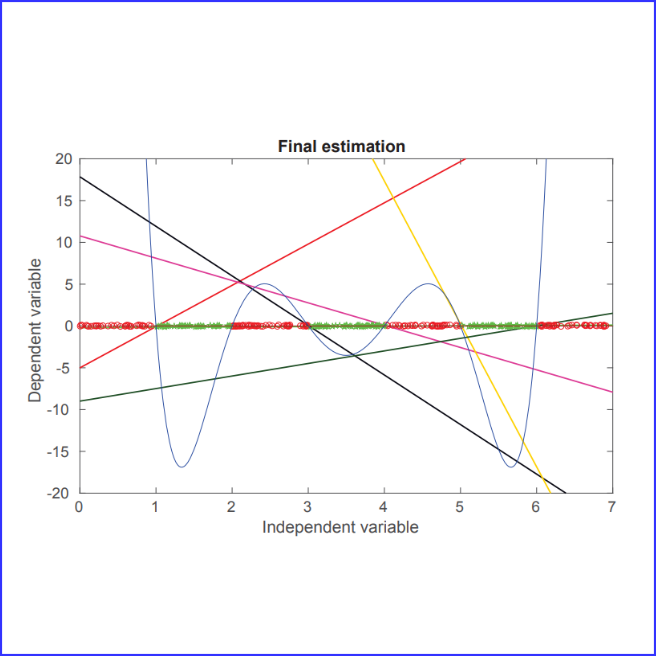
This project compares and implements key model-free Reinforcement Learning (RL)
algorithms, focusing on clarity over complexity. Using online resources for
guidance, it aims to provide accessible, easy-to-understand implementations,
serving as an educational tool for those exploring RL's fundamental concepts.
We developed a multistream Automatic License Plate Recognition
(ALPR) system by assembling an Nvidia deepstream pipeline,
training 3+ models with the Nvidia TAO toolkit, and
periodically sending data streams to a Kafka Apache
for further use cases.
We developed a system to segment and count grapes bunches using
Mask RCNN and DeepSort Tracker.
After that, we extrapolate the counting information to
satellite images to generate heat maps that show the number of
grapes per parcel in a yield.
A compilation of my notes during the second semester of the master program in Artificial Intelligence and Machine Learning. I covered
the following topics: Natural Language Processing, Computational Vision and Imaging, and Current Topics of AI/ML.
A compilation of my notes during the first semester of the master program in Artificial Intelligence and Machine Learning. I covered
the following topics: Machine Learning, Deep Learning, and Mathematics for AI/ML.
Introduction to Pandas library. This short introduction includes 8 jupyter notebooks to understand the
fundamentals and minimum requirements for an job interview.
 , I'm
a computer scientist with experience in AI/ML.
I recently completed a master's degree in AI/ML at the
, I'm
a computer scientist with experience in AI/ML.
I recently completed a master's degree in AI/ML at the